В деталях о работе над A/B-тестами рассказывают Илья Туменко, Publishing Director в AppQuantum, и Олег Семенов, Marketing Lead в Appbooster.

Илья Туменко и Олег Семенов
Материал подготовлен AppQuantum на базе одноименного вебинара.
A/B-тесты: что такое и зачем нужны
A/B-тесты (они же сплит-тесты) — это метод сравнения двух состояний одного элемента. Они помогают повысить конверсию и доходность проекта. Ключевая метрика при их оценке — доход (revenue). Тестируемым элементом может стать что угодно: экран подписки, онбординг, рекламный креатив и т.д.
История появления
A/B-тесты стали популярны в эпоху веб-сайтов, когда их владельцы гнались за повышением конверсии. Они начали менять элементы страниц, чтобы сделать их более привлекательными для посетителей. Но тогда провести тест было гораздо проще.
Выглядело это так: вставлялся тег Google Optimize, а в визуальном редакторе настраивались тестируемые элементы. Затем эксперимент запускался. Пользователи рандомным образом делились на две части. Одна из них получала старый вариант элемента, вторая — измененный.
Со временем A/B-тесты усложнялись и совершенствовались. С развитием мобильного рынка их начали активно использовать для элементов приложений. Но большинство разработчиков избегают A/B-тестов, поскольку принято считать, что проводить их — долго, дорого и трудоемко.
Разберем самые распространенные возражения девелоперов, которые отказываются от A/B-тестов, даже не попробовав.
Работа с возражениями
- Разработчик и без теста знает, как улучшить приложение
С таким заблуждением мы сталкиваемся чаще всего. Девелопер думает, что у него уже достаточно опыта в разработке и дизайне приложений. Он считает, что спокойно может сам исправить все слабые места, после чего показатели мгновенно возрастут. Но, даже опираясь на опыт, не всегда можно сделать правильные выводы и принять верные решения. Даже из закономерностей бывают исключения — универсальных вариантов не существует.
- Можно просто сравнить «до» и «после»
Разработчик убежден, что можно просто вносить изменения одно за другим, сравнивая результаты. При этом часто не учитывается: эффект от изменений наступает не сразу, на это требуется время. К примеру, на это может уйти неделя. Но за эту неделю многое может поменяться. На метрики влияют не только внесенные вами изменения, но и новые конкуренты, стратегия заливки и др.
Чтобы ни один фактор не повлиял на точность результата, два элемента нужно сравнивать одновременно.
- A/B-тесты — это долго и дорого
Это логичное замечание. В мобильных играх зачастую тестируются глубокие продуктовые компоненты. Одним тестом тут не обойтись: чтобы найти оптимум, нужно терпение и деньги.
Тем не менее, оно того стоит.
Мы работали с одним приложением, чья монетизация была построена в том числе на подписках. Около полугода оно работало в убыток (он в пике составлял -$300 тысяч). Проблема была в онбординге и пэйволле. Мы провели более 50 их тестов, нашли подходящие нам по показателям варианты. После этого приложение вышло в плюс, окупила инвестиции, а сегодня приносит стабильный доход в сотни тысяч долларов. Это не было бы возможно без A/B-тестов.
Поэтому единственный честный ответ на возражение, что тестировать долго и дорого: да, это так. Расходы на тестирование придется закладывать в бюджет с самого начала.
Разработка правильной гипотезы
Подготовительный этап к эффективному A/B-тестированию — разработка правильной гипотезы. Каждая гипотеза создается для того, чтобы повлиять на определенную метрику.
Предположим, мы хотим повысить прибыль и работаем для этого с метрикой удержания (retention rate). Выстраиваем гипотезы, много их тестируем, формулируем гипотезы снова, а метрика остается на том же уровне. В таком случае принято называть метрику неэластичной.
Сформулируйте ожидания внутри команды: на что должна повлиять гипотеза? Что она изменит? Изучите поведение пользователей, особенности продукта, определите желаемый прирост. Все это поможет сформулировать гипотезу, которая действительно будет влиять на метрики. Это сэкономит время, силы и деньги на тесты. В следующем разделе мы расскажем, как еще можно провести эффективные тесты с минимальными затратами.
Секрет дешевых A/B-тестов
1. Статистическая значимость
A/B-тесты можно сделать дешевле, если знать нехитрую лазейку — использовать инструменты статистической значимости.
Например, мы тестируем пэйволлы. Для этогот мы берем только когорту юзеров, дошедших до пэйволла — остальные для нас нерелевантны. В итоге мы получаем 2000 юзеров, которые делятся пополам (по числу тестируемых элементов, у нас их 2). В группе А было 140 конверсий, в группе В — 160.
Разница между вариантами маленькая. Из-за этого непонятно, насколько действенные изменения мы внесли. Вот тут на помощь и приходит статистическая значимость: она определяет, сколько именно пользователей затронуло изменение. Сделать расчеты помогут специальные калькуляторы, ссылки на которые вы найдете ниже.
Калькуляторы оцифровывают запущенный тест и дают понять, как он протекает. При расчете они используют один из двух подходов: классический частотный и байесовский. Первый подход выделяет один лучший из тестируемых вариантов. Второй же позволяет конкретизировать, насколько один из вариантов лучше других в процентах.
Попробуем интерпретировать результат нашего теста через один из самых распространенных калькуляторов Mindbox. Он опирается на классический частотный подход.
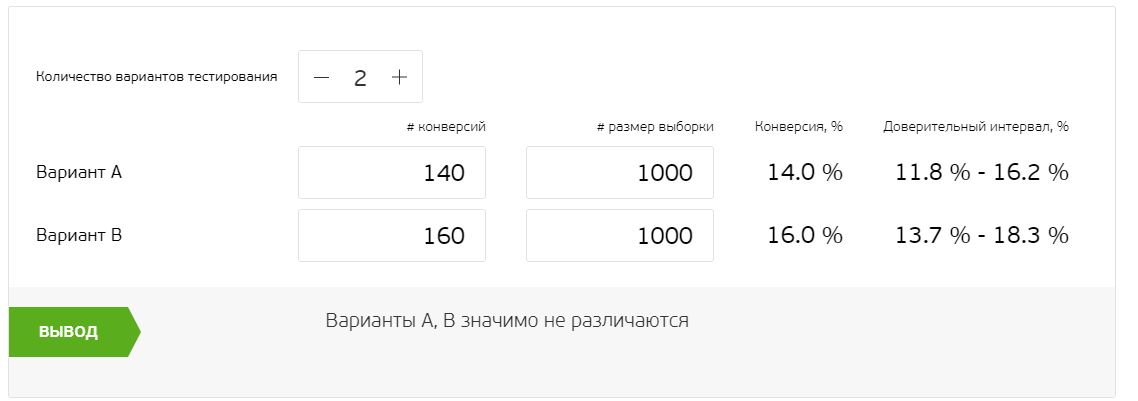
В примере на 1000 юзерах результаты сильно не различаются — сделать четкий вывод не получается. Прогоним те же вводные через калькулятор AB Testguide, использующий байесовский подход.
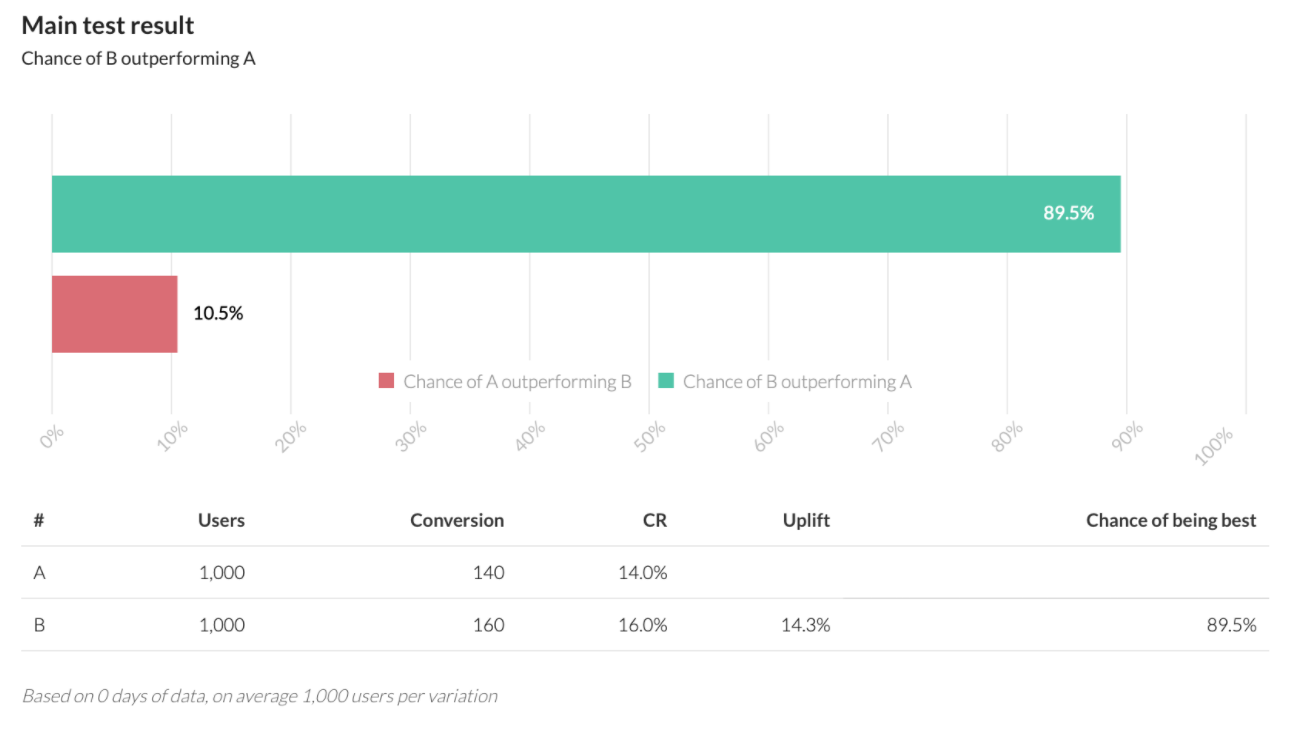
Мы видим, что он дает однозначный ответ: вариант B на 90% успешнее остальных. С байесовским подходом мы экономим время и сокращаем количество итераций теста — соответственно, потраченных денег. Важно понимать, что мы не прогоняем результат через 100 калькуляторов, пока не получим удовлетворяющий итог. Результат в обоих случаях одинаков, а вот интерпретация данных разная.
2. Радикальные тесты
Достичь максимальной эффективности теста при минимальных вложениях также помогут радикальные тесты, где тестируемые варианты максимально далеки от контрольного.
Когда в продуктовой команде только выстраивается процесс работы с тестами, тестировать начинают ближайшие варианты к текущему. Если мы тестируем цены оффера, а изначальное значение — $4, то чаще тестировать начинают $3 и $5. Так делать не стоит.
Мы убеждены, что проводить тесты надо радикально. Контрольная цена оффера $4? Тогда ставьте максимально далекие от нее значения — $1 и $10.
Преимущества радикальных A/B-тестов
- Они показательны. Радикальный тест дает сильно положительный или сильно отрицательный эффект, поэтому нам проще оценить результат изменений. Даже если тест был неудачным, мы понимаем, в какую сторону двигаться. Нерешительный тест внушает иллюзию найденного оптимума. Вариант $5 проиграл по сравнению с вариантом $4 — есть ощущение, что раз проиграл очень близкий к контрольному вариант, остальные бОльшие значения тестировать нецелесообразно, они точно не победят. Из нашего опыта, это не так.
- Можно сэкономить. Итераций в радикальном тесте больше, но стоят они дешевле и достигают нужной значимости на меньшем числе конверсий. Нам требуется меньше данных для уверенного вывода.
- Ниже погрешность. Чем ближе тестируемые варианты, тем выше вероятность случайности.
- Шанс приятной неожиданности. Однажды мы в AppQuantum тестировали очень высокую цену на оффер — $25. Вся наша команда и партнеры-разработчики были уверены, что это слишком дорого, и никто по такой цене покупать не будет. Аналогичный по содержанию оффер у конкурентов стоил максимум $15. Но наш вариант в итоге победил. Приятные неожиданности случаются!
3. Ухудшающие тесты
Быстрый и дешевый способ проверить гипотезу — сделать ухудшающий тест. Его суть в том, что вместо улучшения элемента мы сильно его ухудшаем или просто исключаем. В абсолютном большинстве случаев это проще и быстрее, потому что на разработку хорошего решения разработчик должен потратить деньги, время и силы, и еще не факт, что улучшение поднимет метрики.
Пример ухудшающего теста
Из отзывов пользователей разработчик понял, что в приложении неправильный туториал. Он убежден, что сейчас исправит все ошибки, и метрики возрастут. Если улучшение должно поднять метрики — получается, ухудшение должно их «уронить»? Раз так, можно ухудшить туториал и посмотреть, насколько метрики реально поддаются изменениям. Уже после того, как разработчик убедился, что изменения имеют смысл, можно приступать к улучшению элемента, вкладывая в это силы, время и деньги.
Однако это не значит, что подобный ухудшающий элемент должен быть сделан плохо. Иногда среднее или плохое качество реализации тестируемого элемента — хуже, чем какая-либо реализация в принципе. В этом случае даже ухудшающий тест может дать положительный результат.
На чем стоит проводить ухудшающие тесты:
- нарратив и качество локализации (исключение: narrative-driven жанры и вертикали);
- пользовательский интерфейс (исключение: офферы и пэйволлы;)
- User Experience (в этом случае ухудшающий тест влияет на активность и отзывы о приложении);
- туториал и онбординг (изменения в них дают эффект, но зачастую не настолько значительные, как ожидается).
4. Много изменений за тест
Чаще всего неэффективно тестировать сразу несколько изменений за раз. Нет смысла тестировать 10 элементов, если результат 8 из них очевиден. Но из каждого правила есть исключения: иногда можно протестировать сразу много вариантов ради экономии на тесте.
Вносить много изменений за раз можно, когда:
- мы знаем, что изменения работают эффективно только в совокупности;
- мы уверены, что ни одно из них не сработает в минус;
- за раз проще протестировать сразу несколько недорогих в производстве элементов.
***
Мы разобрались, как проводить дешевые тесты. Теперь попробуем разобраться, как рассчитывать их результат максимально точно, чтобы сократить время и силы на их проведение.
Юнит-экономика в A/B-тестировании
При поиске самых перспективных мест в воронке вашего продукта рекомендуем использовать методы юнит-экономики. Она помогает определить прибыльность бизнес-модели по доходу от одного товара или клиента. В мобильных приложениях доход составляют продажи приложения или подписки или выручка с рекламы.
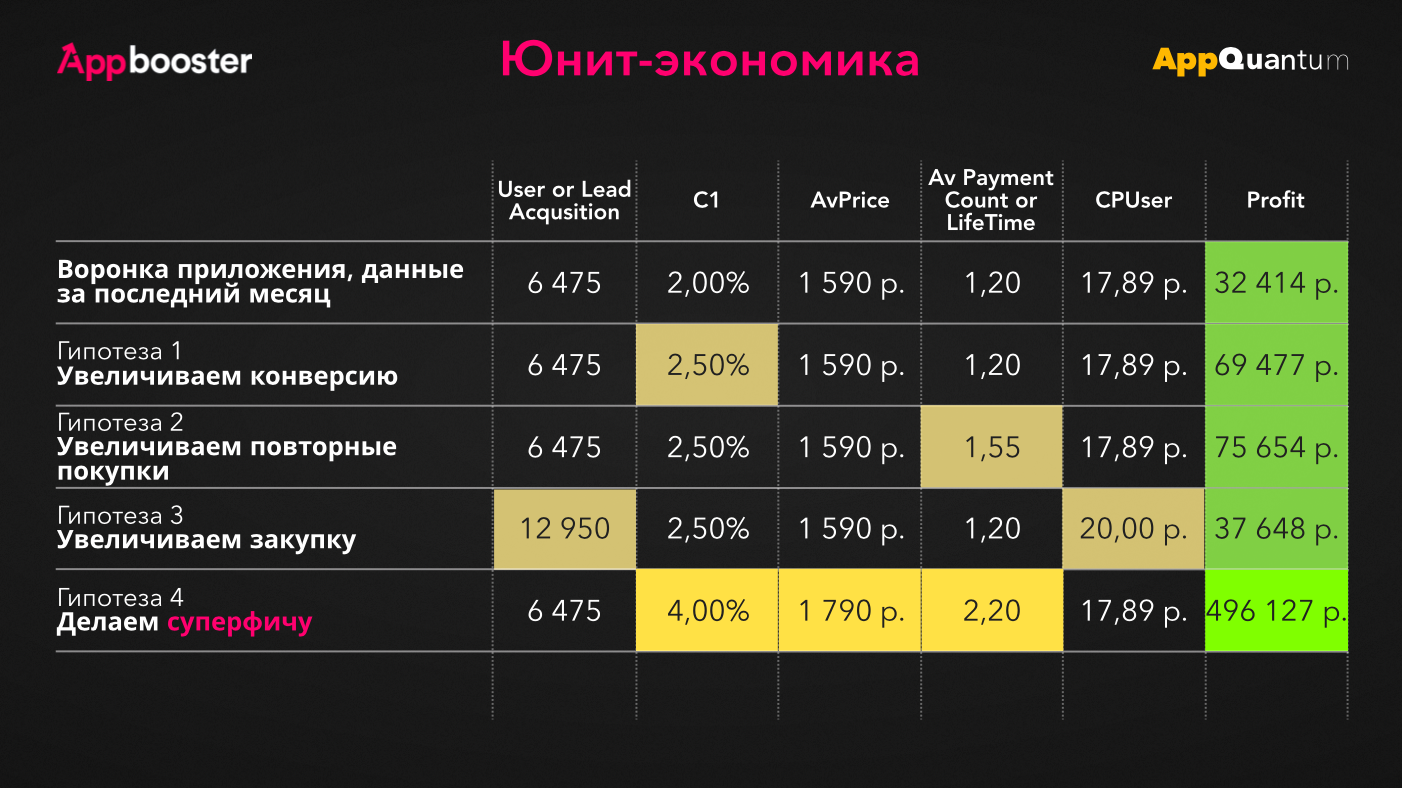
На схеме — пример реального приложения: 4 гипотезы и расчет профита от них с помощью юнит-экономики. Мы упразднили промежуточные метрики, оставив главные: число пользователей в закупке, конверсию клиента, среднюю цену, количество покупок на платящего юзера, стоимость юзера и профит с потока.
Гипотеза 1
Мы хотим поднять конверсию в клиентах. Добьемся прироста на 0,5% — это принесет 69 477 руб.
Гипотеза 2
Мы хотим увеличить повторные покупки. 20 клиентов делают 24 покупки, а нам нужно добиться, чтобы 20 клиентов делали 31 покупку. Концентрация на конкретных метриках и четкая формулировка задачи помогают очертить круг возможных гипотез. Что мы будем делать? Возможно, проведем push-кампанию или будем давать игроку меньше жизней.
Результат — профит уже 75 654 руб.
Гипотеза 3
Увеличим закупку: будем закупать вдвое больше пользователей. Итог — 37 648 руб. Получается, это принесет нам ощутимо меньше денег по сравнению с первым и текущим профитом.
Гипотеза 4
На каком-то этапе изучения юнит-экономики команду посещает идея сделать со своим продуктом что-то совершенно невообразимое. Например, создать суперфичу, которая повысит сразу несколько метрик и принесет 496 127 руб. На первый взгляд, проблема только в том, что ее разработка займет 3 месяца. Однако есть и другие, которые рассмотрим дальше.
MVP больших фичей
MVP (minimum viable product) — это тестовая версия приложения с минимумом функций. MVP создают для теста гипотез и проверки жизнеспособности продукта.
Большая фича — не самое эффективное решение для поднятия метрик. Продукт может стать слишком сложным, размоется его основная ценность. На фичу будут потрачены время, силы и деньги. А впоследствии еще и окажется, что проблема приложения была вовсе не в том, что в нем нет этой фичи.
Допустим, у нас есть огромное желание сделать большую фичу. Но нам нужна гарантия, что ее вообще нужно внедрять. Как ее получить? Разберемся.
Алгоритм действий:
- вычленяем самые большие бонус- и риск-фичи;
- отвечаем на вопросы, почему она сработает и почему может провалиться;
- прикидываем, стоит ли вообще бонус возможных рисков;
- определяем минимум реализации, чтобы получить бонус;
- формализуем оценку бонуса и риска в тесте;
- в итоге сравниваем вариант не только с контрольной группой, но и с альтернативными.

MVP больших фичей: кейс Doorman Story
Рассмотрим на примере приложения Doorman Story, которое издает AppQuantum. Это тайм-менеджер, в котором игрок развивает собственный отель. Работник отеля должен обслужить посетителей за ограниченное время. У каждой игровой механики есть таймер и последовательность действий.
Мы подумали: а что, если механики, открывающиеся пользователю в других играх бесплатно, мы будем продавать? Это выгодная точка монетизации: не нужно производить новый контент, но уже сейчас можно продавать существующий. Для теста этой гипотезы надо было изменить баланс уровней, переделать возможности получения механик, продумать интерфейс их открытия.
Совместно с партнерами из Red Machine (студия-разработчик Doorman Story) мы придумали максимально облегченный вариант суперфичи. Создали уникальную игровую механику платного автомата с жвачкой, которая не влияет на весь игровой баланс и встречается только в одном сете уровней. Одна механика, один арт — экономика приложения при этом не нарушается.
Этот пример ложится в метод MVP больших фичей: выделяем главный бонус и главный риск. Бонус — мы получаем возможность продавать то, что уже есть, не тратясь дополнительно. Риск — игрока может отпугнуть то, что в открытом доступе у него больше нет всех инструментов, некоторые надо покупать дополнительно. Из-за этого пользователь может даже уйти из продукта.
Мы определились, какой максимум и минимум ожидаем от этой фичи и насколько реализация отразит идею. Отвечаем себе на вопросы: показательно ли будет то, что мы сделаем? Спрогнозируем ли эффект? Сможем ли сделать вывод из эксперимента?
При этом в любой момент можно поменять жесткость пэйволла и посмотреть, будут ли люди продолжать играть. Мы не сможем точно сказать, сколько раз купят эту фичу, если ее купили только раз. Но мы можем предсказать пэйволлы.
Чтобы убедиться, что эта механика действительно будет продаваться, мы должны были поставить пользователя в условия, где он не может не купить. Именно поэтому тест мы проводили сразу с пэйволлом. Это помогло нам понять, насколько автомат с жевачкой — ценная покупка для игрока. Так риск измеряется еще лучше. Если люди уходят, когда видят возможность покупки по низкой цене, но не делают ее — значит, скорее всего, им не нравится геймплей. Если же они отваливаются уже на пэйволле — их не удовлетворяет цена.
Мы определились с тем, какие метрики анализируем, и что примерно ожидаем. Сформулировали три гипотезы к фиче, которую собираемся внедрить. Придумали MVP этих фичей, которые делаются максимум за две недели. Протестировали эти фичи и получили неожиданный результат: в тесте победила фича, на которую не ставил никто из нашей команды и команды партнеров. Самая упрощенная механика и стала победителем. По факту, лучший вариант никто не рассматривал как лучший.
Если бы мы положились на интуицию и не стали проводить тест, то получили бы менее выигрышный результат. A/B-тестирование позволило найти оптимум в кратчайший срок.
Оценка рисков теста
Запуская тест, мы должны оценивать возможные риски: понимать, что может «поломаться» в каждой группе.
Допустим, при росте конверсии в пользователя снижается количество покупок в приложении. Эта ситуация, когда многие юзеры прошли онбординг, но при этом уходят из приложения спустя небольшое время, не заплатив. Это показывает низкий уровень вовлеченности в приложении. И хоть пользователей по факту могло стать больше, зарабатывать с них мы стали меньше.
Или же, наоборот, мы тестируем количество рекламных просмотров. От того, что реклама на каждом экране, пользователь удаляет приложение на второй сессии и больше не возвращается. Поэтому важно находить контр-метрику, за изменениями которой мы тоже будем следить в рамках теста.
Если гипотеза заключается в том, что что-то может испортить пользователю впечатление — лучше всего следить за конверсией по прогрессу и вовлечению. Она напрямую влияет на то, чего мы боимся. Это работает, например, с тем же самым пэйволлом.
Очистка результатов теста
Переходим к интерпретации результатов теста. Чтобы посчитать их объективно, мы должны в первую очередь сегментировать аудиторию.
Варианты сегментации:
- по демографии (чаще страна, иногда пол + возраст. От этого фактора меняются даже каналы привлечения трафика);
- по плательщикам (если хватает данных, делаем несколько сегментов);
- по новым и старым юзерам (если возможно, стоит тестировать только новых юзеров);
- по платформе и источнику.
Важно отфильтровывать тех, кого изменения не затронули. Если мы тестируем какой-то элемент для пользователей, достигших 7-го уровня, то, разумеется, учитываем и тех, кто до этого уровня не добрался, иначе мы получим некорректные метрики. Также отсекаем всех, не прошедших воронку, и любые аномалии.
Проблемы тестов в мобильных приложениях
В мобайле тесты проходят сложнее, дороже и дольше, чем в вебе. Проблемы начинаются на этапе проверки билда в магазине приложений. Чтобы добавить изменение, нужно заново загрузить билд — поэтому немалое время уходит на модерацию. Помимо временных есть денежные затраты: на закупку трафика, дизайн, контроль и обработку теста.
Наличие новейшей версии приложения — еще одно препятствие. Не у всех ваших пользователей может быть его актуальная версия — не все они попадут под тест.
Еще в A/B-тестировании существует проблема «подглядывания» (peeking problem) — смысл в том, что продуктовая команда делает выводы и заканчивает тест досрочно.
Допустим, у разработчика приложения есть любимая версия, которая, как кажется лично ему, должна победить. Чтобы подтвердить свое предположение, он решает высчитать с помощью статистической значимости гипотетически лучший вариант. По подсчетам он видит, что его любимая версия действительно имеет высокий шанс победить. Основываясь только на этой информации, он останавливает тест досрочно, чтобы сократить время и стоимость теста. Хотя технически тест еще не завершился, потому что не все пользователи успели пройти через тестируемый элемент.
Зачастую это решение принимается слишком скоропостижно. Да, мы можем предсказать примерный результат теста, но далеко не всегда это действительно работает. Вывод мог бы быть другим, если бы разработчик прогнал всю выделенную под версию аудиторию через тест. Поэтому «подглядывать» в результаты теста можно, но всегда нужно дожидаться, пока через него пройдет вся выборка пользователей.
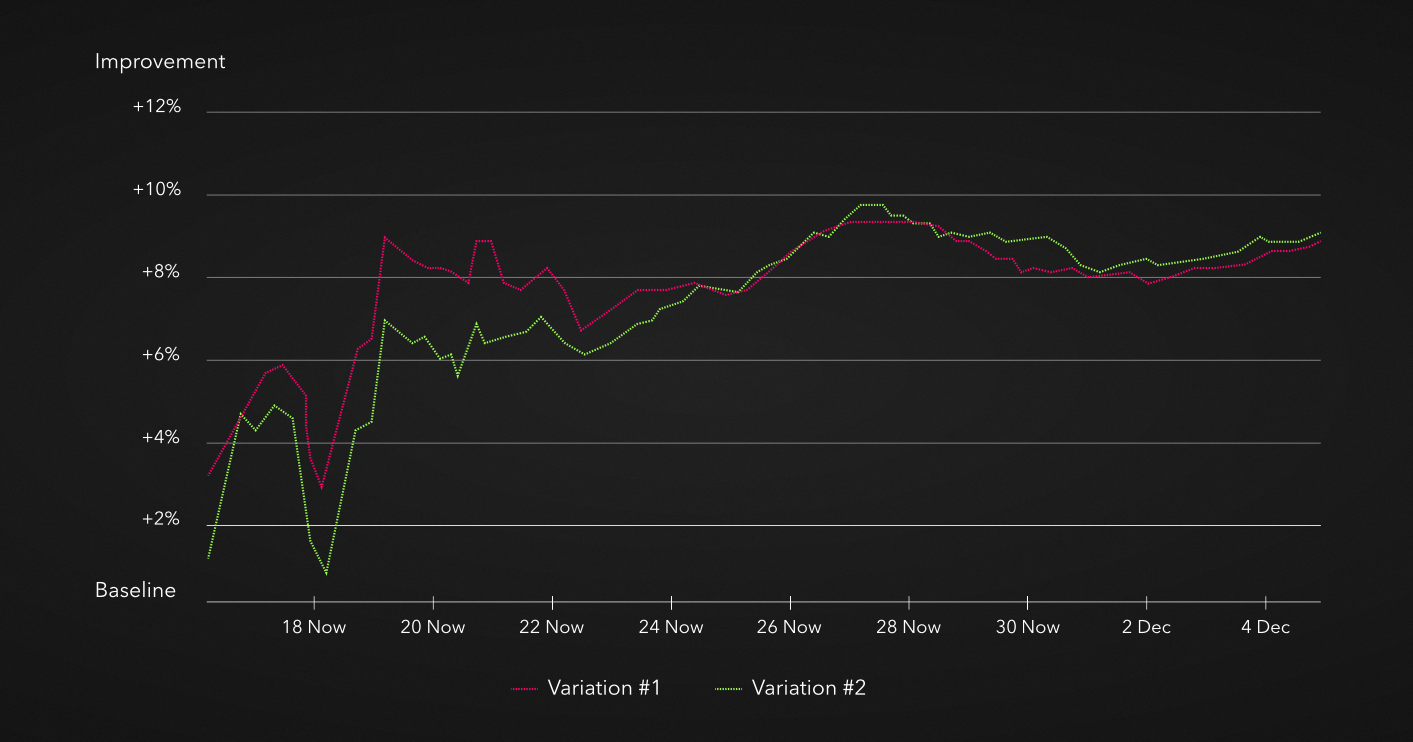
Нужно также учитывать демографический момент: в разных странах побеждают разные варианты. Поэтому не факт, что лучший вариант в США выиграет и в России.
Помимо перечисленных, одна из ключевых проблем тестов: изменение реальности. Именно поэтому вариант, который был выигрышным еще вчера, не обязательно будет выигрышным сегодня.
Байесовский бандит
Перейдем к самым удобным, современным и быстрым A/B-тестам: так называемому «байесовскому многорукому бандиту». Он представляет собой тесты, обновляемые в режиме реального времени на основе эффективности вариации. Самой эффективной группе отдается наибольшая доля. Проще говоря, это автооптимизация.
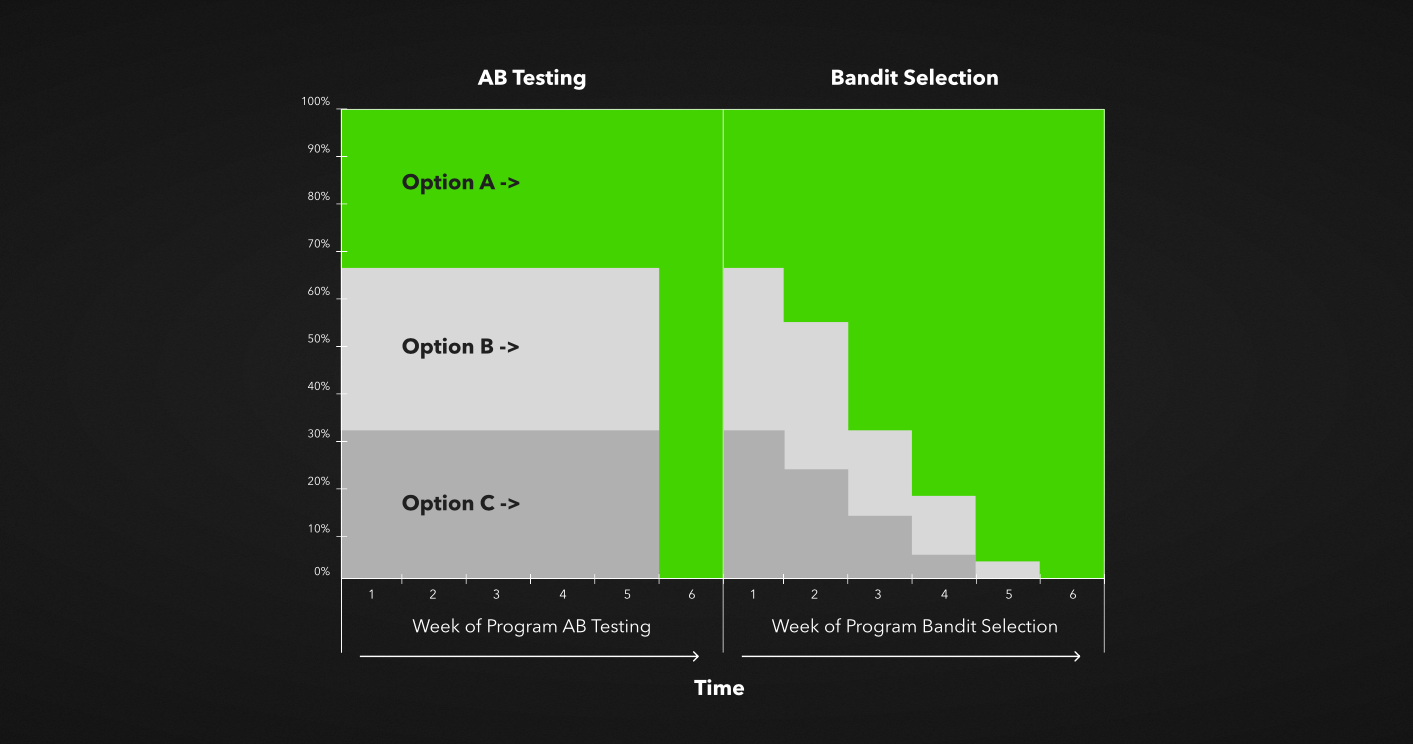
Как мы видим на картинке, если вариант A побеждает, на следующий день мы увеличиваем долю пользователей, которым выдается именно он. Если на третий день видим, что он снова побеждает, дальше увеличиваем его долю. В итоге победившая группа раскатывается на 100%.
Байесовский бандит адаптируется ко времени и изменениям. Он экономит время на то, чтобы прописывать сегменты вручную и анализировать их. Это помогает избежать проблемы подглядывания и экономит на контроле. Самое главное: это автоматическое создание новых тестов, которые в любом продуктовом бизнесе реализовать дорого и сложно.
Да, тесты — это много ручной работы. Но если есть механизм, автоматически определяющий хорошие и плохие варианты, то он станет подспорьем для автоматических тестов.
Как понять, что вы готовы к A/B-тестам
Вы готовы к A/B-тестированию, если у вас:
- есть внедренная аналитика и трекинг в приложении;
- сведена экономика (вы понимаете, во сколько обойдется один пользователь и можете это масштабировать);
- есть ресурсы для системной проверки гипотез.
Вывод: А/B-тесты можно проводить быстро, дешево и легко, если знать, как это делать. И делать это нужно систематически. Суть не в том, чтобы запустить тест один раз и забыть об этом навсегда. Качественный эффект вы получите только через цепочки изменений.